1 Introduction

1.1 Chapter Map
- Define RLVR as learning from verifiable reward signals and explain verifiable tasks.
- Analyze why RLVR became central to reasoning models and preview the structure of the book.
1.2 What RLVR Is
RLVR is reinforcement learning on tasks where some meaningful part of correctness can be checked directly. The check you implement can be exact, as in symbolic math or formal proof, or the result of an executable, as in unit tests. It can be partial, i.e. grounded question answering or tool-using agents where only some parts of the trajectory can be reliably scored. The unifying idea is the availability of a success notion. Once a task exposes useful correctness signals, reinforcement learning can optimize against them, search can exploit them at test time, and systems can improve far beyond what static supervised fine-tuning alone produces.
We use verifier as the default term for the mechanism that checks output and produces a signal, related terms include checker, scorer, and sometimes judge.
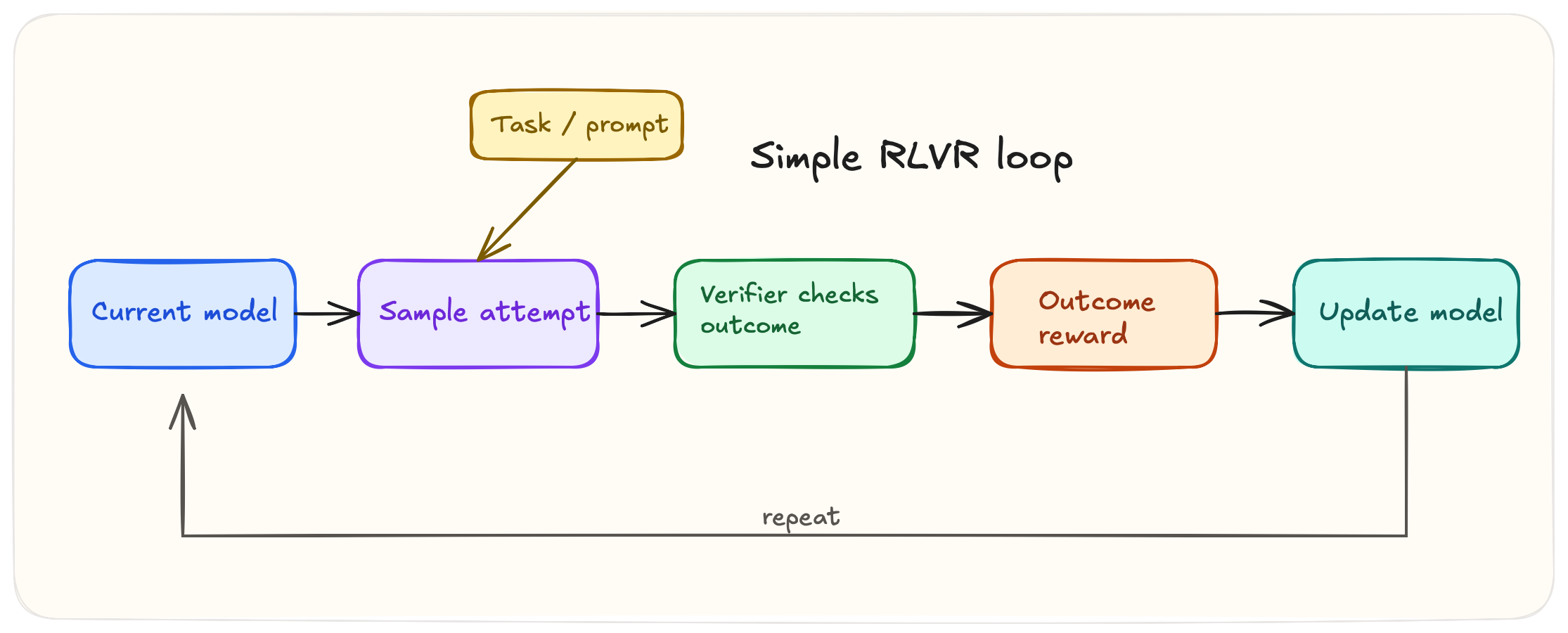
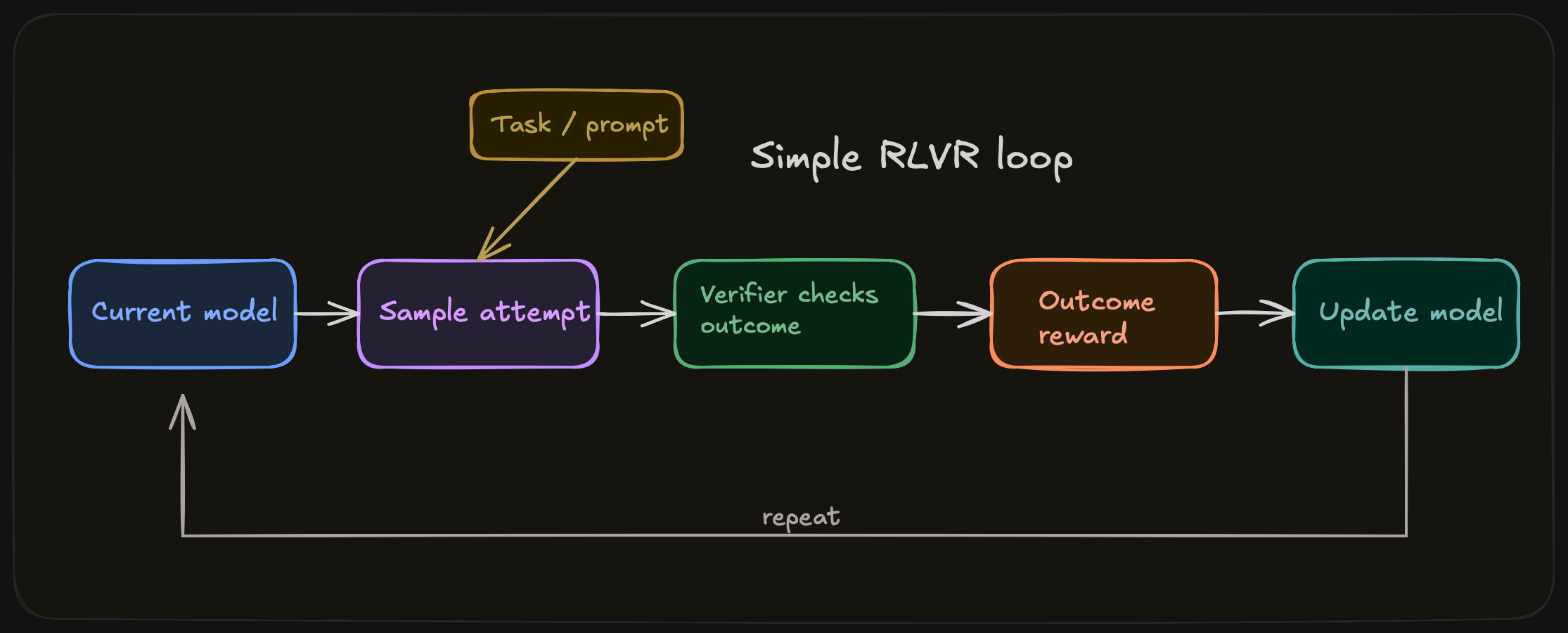
1.3 Origins of RLVR
In some sense RLVR is akin to the oldest paradigm in reinforcement learning, since it learns from direct reward rather than preference comparison, just like the classic RL environemnts, e.g. cartpole; what is new is the application to LLMs through verifiers that can check answers, code, proofs, and traces.
I personally reflect back on the advent of reasoning models and reinforcement learning through a strange amnesia of an idea so simple with hindsight, but which took two years after ChatGPT to discover. This assessment, however, is unfair in the sense that the idea to make models think step by step long predates the 2024 reasoning-model wave.1 The broader prompting paradigm emerged across late 2021 and early 2022: scratchpads for intermediate computation appeared first, chain-of-thought prompting then formalized the use of intermediate reasoning traces, and the exact prompt “Let’s think step by step” was popularized a few months later.
Before the reasoning-model wave of 2024, code generation had already explored reinforcement learning against executable verifiers: CodeRL (July 5, 2022), PPOCoder (January 31, 2023), and RLTF (July 10, 2023) all trained language models using unit tests or execution feedback as objective reward signals.2
DeepSeekMath, published on February 5, 2024, was the first major open paper to apply verifier-driven RL to mathematical reasoning at LLM scale via the introduction of GRPO.
Things heated up in September 2024, when OpenAI published “Learning to Reason with LLMs” (o1), indicating that they had used a train-time and test time compute strategy to enhance model reasoning through reinforcement learning in math, and coding tasks.3 The name “Reinforcement Learning with Verifiable Rewards” (RLVR) was coined in the Tulu 3 paper from November 22, 2024.4 Finally, there was DeepSeek-R1 at the start of 2025, which demonstrated the full verifier-driven RL formula for bootstrapping reasoning models.5 To quote someone describing the atmosphere at Meta after R1 launched, “Engineers are moving frantically to dissect DeepSeek and copy anything and everything we can from it,” and according to Fortune, there were war rooms assembled at Meta to understand how a Chinese lab with substantially less resources was beating them.6
The trend we can extract from this short history is that model improvement increasingly depended on checkable interfaces.
1.4 Verifiable Tasks
Tasks admit verifiable rewards when there is an interface to separate better behavior from worse behavior at acceptable cost. Math problems allow answer checking up to normalization. Code can be run against visible and hidden tests. Formal proof systems can accept or reject proof states under explicit rules. These domains became central not because they expose unusually clean signals.
Other tasks are weaker but still useful. Long-context question answering may permit citation checks, evidence matching, or entailment-style grading. Tool-using agents have environment transitions, task completion criteria, or execution traces. These signals are often noisier, more expensive, and easier to exploit, but they can still support learning if the reward channel is informative enough.
The takeaway is that there isn’t a uniform notion of determining correctness across all conceivable tasks. It is strongest where correctness is legible and weakest where the reward channel is sparse, ambiguous, or only loosely coupled to the capabilities we want.
A useful way to see the space is as a domain map. One axis is verification strength: how cleanly the checker separates better behavior from worse behavior. The other is verification granularity: whether the checked object is a coarse final artifact, a partially grounded intermediate object, or a fine-grained trajectory.(Shao et al. 2024; Liu et al. 2023; Xin et al. 2024; Zhang et al. 2024; Lu et al. 2023; Zhou et al. 2023; Xie et al. 2024)
Hover over a domain
- Summary
- The detail panel updates as you move around the map.
- Verifiable
- Failure modes
1.5 RLVR and Reasoning
RLVR and reasoning go hand in hand, but they are different. The former is a training paradigm, and the latter is a downstream capability/artefact, e.g. multi-step breakdown, search, planning, tool use, etc. The marriage between the two occurs because the most successful reasoning domains are exactly the ones with strong verifiers: math, code, proofs, some grounded QA. The result is that some of the most important progress in reasoning models has come from learning against verifiable rewards. It’s therefore understandable that RLVR and reasoning are conflated, since verifier-friendly domains are the best places to scale reasoning performance.
1.6 Verifiable versus Complete
Even verifiers are susceptible to becoming proxies, from our three core domain examples:
- A code evaluator may miss behaviors outside the test suite.
- A math reward may depend on brittle extraction.
- A proof system may validate a derivation without telling us whether the model’s decomposition was insightful or robust.
These examples raise important questions to consider in applying RLVR:
- what is being checked,
- what is being missed,
- how expensive is the check, and
- how easily the signal can be gamed.
We will dissect the gap between a usable reward signal and the outcome we want in the rest of the book.
1.7 What This Book Covers
The next chapters move from the general paradigm to the main reward regimes in practice. Chapters 2 through 4 cover outcome rewards, process rewards, programmatic, learned and hybrid verification pipelines. Chapter 5 demonstrates turning a verifier into a learning signal. Chapter 6 turns to search and test time verification, and Chapter 7 covers reward hacking. Chapter 8 reconstructs a frontier RLVR recipe. Chapter 9 compares the paradigm across its strongest and most difficult domains. Chapter 10 closes with the open problems.
A useful compressed lineage runs from scratchpads in late 2021, to chain-of-thought prompting in January 2022, to the exact zero-shot prompt “Let’s think step by step” in May 2022 (Nye et al. 2021; Wei et al. 2022; Kojima et al. 2022).↩︎
CodeRL was submitted on July 5, 2022 and used unit tests and a critic model to guide program synthesis (Le et al. 2022). PPOCoder was submitted on January 31, 2023 and used execution-based feedback with PPO (Shojaee et al. 2023). RLTF was submitted on July 10, 2023 and used online unit-test feedback of multiple granularities for code LLMs (Liu et al. 2023).↩︎
OpenAI’s writeup states that
o1performance improved with both more reinforcement learning, which they describe as train-time compute, and more time spent thinking at test time (OpenAI 2024).↩︎DeepSeekMath introduced GRPO and used RL to improve mathematical reasoning in an open model (Shao et al. 2024). Tulu 3 later introduced the name “Reinforcement Learning with Verifiable Rewards (RLVR)” for this broader training pattern (Lambert et al. 2024).↩︎
DeepSeek-R1 argues that reasoning abilities can be incentivized through pure reinforcement learning on verifiable tasks such as mathematics, coding competitions, and STEM fields (DeepSeek-AI et al. 2025).↩︎
The quoted line was reported as an anonymous Teamblind post summarized by TMTPOST, while the claim that Meta created four “war rooms” was reported by Fortune, citing The Information (TMTPOST Global 2025; Quiroz-Gutierrez 2025).↩︎